
(experimental) Badge Visualizations#
Badge status#
Warning
this is not guaranteed to stay up to date with current, but the listed date is accurate. You can see the code that generates the figure behind the “click to show” button. It is Python code that you should be able to run anywhere with the required libraries installed.
Show code cell source
%matplotlib inline
import os
from datetime import date,timedelta
import calendar
import pandas as pd
import numpy as np
import seaborn as sns
from myst_nb import glue
# style note: when I wrote this code, it was not all one cell. I merged the cells
# for display on the course website, since Python is not the main outcome of this course
# semester settings
first_day = date(2023,1,24)
last_day = date(2023,5,1)
meeting_days =[1,3] # datetime has 0=Monday
spring_break = (date(2023,3,11),date(2023,3,19))
penalty_free_end = date(2023, 2, 9)
# enumerate weeks
weeks = int((last_day-first_day).days/7+1)
# create differences
mtg_delta = timedelta(meeting_days[1]-meeting_days[0])
week_delta = timedelta(7)
skips = [date(2023,2,28)]
weeks = int((last_day-first_day).days/7+1)
meeting_days =[1,3]
mtg_delta = timedelta(meeting_days[1]-meeting_days[0])
week_delta = timedelta(7)
during_sb = lambda d: spring_break[0]<d<spring_break[1]
possible = [(first_day+week_delta*w, first_day+mtg_delta+week_delta*w) for w in range(weeks)]
weekly_meetings = [[c1,c2] for c1,c2 in possible if not(during_sb(c1))]
meetings = [m for w in weekly_meetings for m in w if not(m in skips)]
# build a table for the dates
badge_types = ['experience', 'review', 'practice']
target_cols = ['review_target','practice_target']
df_cols = badge_types + target_cols
badge_target_df = pd.DataFrame(index=meetings, data=[['future']*len(df_cols)]*len(meetings),
columns=df_cols).reset_index().rename(
columns={'index': 'date'})
# set relative dates
today = date.today()
start_deadline = date.today() - timedelta(7)
complete_deadline = date.today() - timedelta(14)
# mark eligible experience badges
badge_target_df['experience'][badge_target_df['date'] <= today] = 'eligible'
# mark targets, cascading from most recent to oldest to not have to check < and >
badge_target_df['review_target'][badge_target_df['date'] <= today] = 'active'
badge_target_df['practice_target'][badge_target_df['date'] <= today] = 'active'
badge_target_df['review_target'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['practice_target'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['review_target'][badge_target_df['date']
<= complete_deadline] = 'completed'
badge_target_df['practice_target'][badge_target_df['date']
<= complete_deadline] = 'completed'
# mark enforced deadlines
badge_target_df['review'][badge_target_df['date'] <= today] = 'active'
badge_target_df['practice'][badge_target_df['date'] <= today] = 'active'
badge_target_df['review'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['practice'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['review'][badge_target_df['date']
<= complete_deadline] = 'completed'
badge_target_df['practice'][badge_target_df['date']
<= complete_deadline] = 'completed'
badge_target_df['review'][badge_target_df['date']
<= penalty_free_end] = 'penalty free'
badge_target_df['practice'][badge_target_df['date']
<= penalty_free_end] = 'penalty free'
# convert to numbers and set dates as index for heatmap compatibility
status_numbers_hm = {status:i+1 for i,status in enumerate(['future','eligible','active','penalty free','started','completed'])}
badge_target_df_hm = badge_target_df.replace(status_numbers_hm).set_index('date')
# set column names to shorter ones to fit better
badge_target_df_hm = badge_target_df_hm.rename(columns={'review':'review(e)','practice':'practice(e)',
'review_target':'review(t)','practice_target':'practice(t)',})
# build a custom color bar
n_statuses = len(status_numbers_hm.keys())
manual_palette = [sns.color_palette("pastel", 10)[7],
sns.color_palette("colorblind", 10)[2],
sns.color_palette("muted", 10)[2],
sns.color_palette("colorblind", 10)[9],
sns.color_palette("colorblind", 10)[8],
sns.color_palette("colorblind", 10)[3]]
# generate the figure, with the colorbar and spacing
ax = sns.heatmap(badge_target_df_hm,cmap=manual_palette,linewidths=1)
# mote titles from bottom tot op
ax.xaxis.tick_top()
# pull the colorbar object for handling
colorbar = ax.collections[0].colorbar
# fix the location fo the labels on the colorbar
r = colorbar.vmax - colorbar.vmin
colorbar.set_ticks([colorbar.vmin + r / n_statuses * (0.5 + i) for i in range(n_statuses)])
colorbar.set_ticklabels(list(status_numbers_hm.keys()))
# add a title
today_string = today.isoformat()
glue('today',today_string,display=False)
glue('today_notdisplayed',"not today",display=False)
ax.set_title('Badge Status as of '+ today_string);
Text(0.5, 1.0, 'Badge Status as of 2023-09-08')
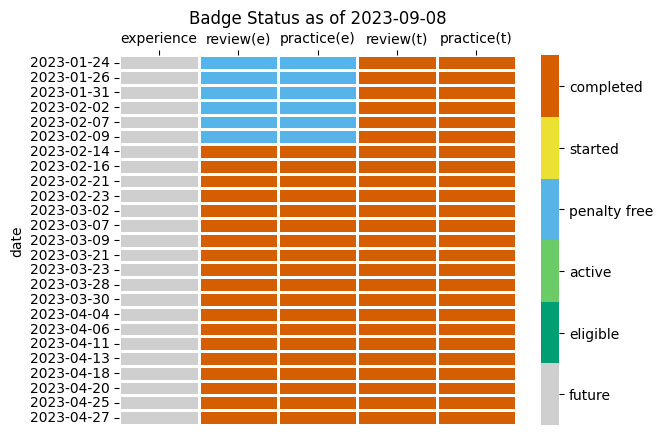
The (e) columns are what will be enforced, the (t) columns is ideal, see the deadlines section of the syllabus for more on the statuses for more detail.
The following table shows, as of ‘2023-09-08’, the number of badges with each status.
Show code cell source
status_list_summary = ['eligible', 'penalty free', 'active', 'started', 'completed']
badge_count_df = badge_target_df[badge_target_df['date']<today].apply(pd.value_counts).loc[status_list_summary].drop(
columns='date').fillna(' ')
glue('exp_ontrack',int(badge_count_df.loc['eligible','experience']),display=False)
glue('exp_min',int(badge_count_df.loc['eligible','experience']-3),display=False)
glue('rp_completed',int(badge_count_df.loc['completed','review_target']),display=False)
glue('rp_started',int(badge_count_df.loc['started','review_target']),display=False)
badge_count_df
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[1], line 2
1 status_list_summary = ['eligible', 'penalty free', 'active', 'started', 'completed']
----> 2 badge_count_df = badge_target_df[badge_target_df['date']<today].apply(pd.value_counts).loc[status_list_summary].drop(
3 columns='date').fillna(' ')
5 glue('exp_ontrack',int(badge_count_df.loc['eligible','experience']),display=False)
6 glue('exp_min',int(badge_count_df.loc['eligible','experience']-3),display=False)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/pandas/core/indexing.py:1103, in _LocationIndexer.__getitem__(self, key)
1100 axis = self.axis or 0
1102 maybe_callable = com.apply_if_callable(key, self.obj)
-> 1103 return self._getitem_axis(maybe_callable, axis=axis)
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/pandas/core/indexing.py:1332, in _LocIndexer._getitem_axis(self, key, axis)
1329 if hasattr(key, "ndim") and key.ndim > 1:
1330 raise ValueError("Cannot index with multidimensional key")
-> 1332 return self._getitem_iterable(key, axis=axis)
1334 # nested tuple slicing
1335 if is_nested_tuple(key, labels):
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/pandas/core/indexing.py:1272, in _LocIndexer._getitem_iterable(self, key, axis)
1269 self._validate_key(key, axis)
1271 # A collection of keys
-> 1272 keyarr, indexer = self._get_listlike_indexer(key, axis)
1273 return self.obj._reindex_with_indexers(
1274 {axis: [keyarr, indexer]}, copy=True, allow_dups=True
1275 )
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/pandas/core/indexing.py:1462, in _LocIndexer._get_listlike_indexer(self, key, axis)
1459 ax = self.obj._get_axis(axis)
1460 axis_name = self.obj._get_axis_name(axis)
-> 1462 keyarr, indexer = ax._get_indexer_strict(key, axis_name)
1464 return keyarr, indexer
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/pandas/core/indexes/base.py:5877, in Index._get_indexer_strict(self, key, axis_name)
5874 else:
5875 keyarr, indexer, new_indexer = self._reindex_non_unique(keyarr)
-> 5877 self._raise_if_missing(keyarr, indexer, axis_name)
5879 keyarr = self.take(indexer)
5880 if isinstance(key, Index):
5881 # GH 42790 - Preserve name from an Index
File /opt/hostedtoolcache/Python/3.8.18/x64/lib/python3.8/site-packages/pandas/core/indexes/base.py:5941, in Index._raise_if_missing(self, key, indexer, axis_name)
5938 raise KeyError(f"None of [{key}] are in the [{axis_name}]")
5940 not_found = list(ensure_index(key)[missing_mask.nonzero()[0]].unique())
-> 5941 raise KeyError(f"{not_found} not in index")
KeyError: "['active', 'started'] not in index"
This means that, as of ‘2023-09-08’ you are fully caught up if you have:
experience badges submitted.
total review and practice badges completed.
additional review and/or practice badges started and in progress.
Notes:
If you do not have at least experience badges earned, you should visit office hours to get caught up.
There are are 6 review and practice badges that are from the penalty free zone, so they never expire.
Most of your experience and completed badges should be earned, but there is no deadline to fix issues with them.
Prepare work and Experience Badges Process#
This is for a single example with specific dates, but it is similar for all future dates
The columns (and purple boxes) correspond to branches in your KWL repo and the yellow boxes are the things that you have to do. The “critical” box is what you have to wait for us on. The arrows represent PRs (or a local merge for the first one)
In the end the commit sequence for this will look like the following:
Where the “approved” tag represents and approving reivew on the PR.
Review and Practice Badge#
Legend:
This is the general process for review and practice badges