How does timing work?
Contents
21. How does timing work?#
22. How do clocks impact computing?#
22.1. Recall our model Computer#

We have talked about the ALU at length and we have touched on memory, but next we will start to focus on the Control unit.
We discussed that the operations we need to carry out is mostly
22.2. Control Unit#
The control unit converts binary instructions to signals and timing to direct the other components.
22.2.1. What signals?#
We will go to the ALU again since the control unit serves it to figure out what it needs.
Remember in the ALU, has input signals that determine which calculation it will execute based on the input.
22.2.2. Why Timing signals?#
Again, the ALU itself tells us why we need this, we saw that different calculations the ALU does take different amount of times to propagate through the circuit.
Even adding numbers of different numbers that require different number of carries can take different amount of times.
So the control unit waits an amount of time, that’s longer than the slowest calculation before sending the next instruction. It also has to wait that long before reading the output of the ALU and sending that result to memory as needed.
22.3. What is a clock?#
In a computer the clock refers to a clock signal, historically this was called a logic beat. This is represented by a sinusoidal (sine wave) or square (on, off, on, off) signal that operates with a constant frequency.
This has changed a lot over time.
The first mechanical analog computer, the Z1 operated at 1 Hz, or one cycle per second; its most direct successor moved up to 5-10Hz; later there were computers at 100kHz or 100,000Hz, but where one instruction took 20 cycles, so it had an effective rate at 5kHz.
Try it Yourself
Look up the CPU speed of your computer and your phone. How do they compare.
22.4. Execution Times#
We’ll get back to our inclass directory.
cd Documents/inclass/systems/
Then we can do a familiar command
grep "index" fall2022/_practice/*
fall2022/_practice/2022-09-14.md:```{index} gitoffline.md
fall2022/_practice/2022-09-26.md:```{index} abstraction.md
fall2022/_practice/2022-09-26.md:```{index} assemblyexplore.md
fall2022/_practice/2022-09-28.md:```{index} worflows.md
fall2022/_practice/2022-10-03.md:```{index} offlineissue.md
fall2022/_practice/2022-10-05.md:```{index} gitplumbingdetail.md
fall2022/_practice/2022-10-12.md:```{index} numbers.md
fall2022/_practice/2022-10-17.md:1. Add that to the index
fall2022/_practice/2022-10-17.md:1. Add the tree from the first commit to the index as a subdirectory with `git read-tree --prefix=back <hash>`
fall2022/_practice/2022-10-17.md:```{index} gitplumbingdetail.md
fall2022/_practice/2022-10-17.md:```{index} test_repo_map.md
We can test it how long it takes.
time grep "index" fall2022/_practice/*
fall2022/_practice/2022-09-14.md:```{index} gitoffline.md
fall2022/_practice/2022-09-26.md:```{index} abstraction.md
fall2022/_practice/2022-09-26.md:```{index} assemblyexplore.md
fall2022/_practice/2022-09-28.md:```{index} worflows.md
fall2022/_practice/2022-10-03.md:```{index} offlineissue.md
fall2022/_practice/2022-10-05.md:```{index} gitplumbingdetail.md
fall2022/_practice/2022-10-12.md:```{index} numbers.md
fall2022/_practice/2022-10-17.md:1. Add that to the index
fall2022/_practice/2022-10-17.md:1. Add the tree from the first commit to the index as a subdirectory with `git read-tree --prefix=back <hash>`
fall2022/_practice/2022-10-17.md:```{index} gitplumbingdetail.md
fall2022/_practice/2022-10-17.md:```{index} test_repo_map.md
real 0m0.004s
user 0m0.001s
sys 0m0.002s
We get three times:
real: wall clock time, the total time that you wait for the the process to execute
user: CPU time in user mode within the the process, the time the CPU spends executing the process itself
sys: CPU time spent in the kernel within the process, the time CPU spends doing operating system interactions associated with the process
The real time includes the user time, the system time, and any scheduling or waiting time that that occurs.
22.5. Systems vs Application Programming#
most of you will do a lot more application programming than systems programming
knowing how the systems stuff works is important because you will need to interact with it.
22.6. Threading#
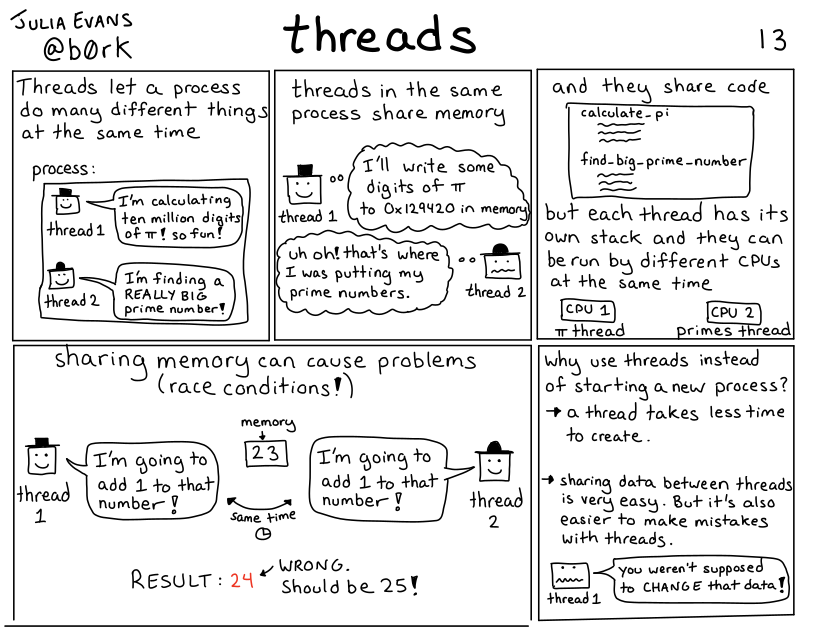
We are going to pretend that summing squares of numbers is expensive computation and we want to spread it across different multiple cores. To do that, we spread it into separate threads.
nano sq_sum_threaded.c
This program is:
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h>
/* single global variable */
/* shared, accessible, modifiable by all threads */
int accum = 0;
void* square(void* x) {
int xi = (int)x;
accum += xi * xi;
return NULL; /* nothing to return, prevent warning */
}
int main(int argc, char** argv) {
int i;
pthread_t ths[20];
for (i = 0; i < 20; i++) {
pthread_create(&ths[i], NULL, square, (void*)(i + 1));
}
for (i = 0; i < 20; i++) {
void* res;
pthread_join(ths[i], &res);
}
printf("accum = %d\n", accum);
return 0;
}
Then we can build the program.
gcc -pthread -Wall -g -o sqsum sq_sum_threaded.c -lm
We can both compile and link it at once and we get just a warning
sq_sum_threaded.c:19:43: warning: cast to 'void *' from smaller integer type 'int'
[-Wint-to-void-pointer-cast]
pthread_create(&ths[i], NULL, square, (void*)(i + 1));
^
1 warning generated.
` and we can run the program
./sqsum
I got the wrong answer
accum = 2861
To confirm, let’s do it in python:
python
Python 3.8.3 (default, Jul 2 2020, 11:26:31)
[Clang 10.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> sum([i**2 for i in range(1,20)])
2470
>>> sum([i**2 for i in range(1,21)])
2870
>>> exit()
We saw that different students got different answers.
We can use a for loop in bash to explore this further and figure out why.
for i in {1..1000}; do ./sqsum; done | sort | uniq -c
this also uses some new bash commands:
sortorders all of the outputs of the 1000 runs of our programand
uniqwith the-coption counts how many times any given result appeart multiple times
1 accum = 2331
1 accum = 2434
2 accum = 2509
2 accum = 2614
2 accum = 2701
1 accum = 2757
2 accum = 2770
2 accum = 2806
1 accum = 2817
4 accum = 2821
2 accum = 2834
9 accum = 2845
4 accum = 2854
15 accum = 2861
15 accum = 2866
2 accum = 2869
935 accum = 2870
So, this time I got the right answer most of the times 955 out of 1000, but lots of other answers at least once.
To understand what happens, lets look at the following program, which should be an equivalent way to implement the body of the square function.
int temp = accum;
temp += x * x;
accum = temp;
In this one, we first copy the accum value to a temporary variable, then square the value and add that to temp, and then finally add that value back to accum. This should be equivalent to the program above, result wise.
Even though this is not how we wrote our program, this is actually what it has to do, as we spin out each process.
This table traces through what occurs in two threads.
// Thread 1 |
// Thread 2 |
Status |
|
|
now |
`temp2 += 2 * 2; |
now temp2 = 4 |
|
temp1 += 1 * 1; |
// temp1 = 1 |
|
accum = temp1; |
// accum = 1 |
|
accum = temp2; |
// accum = 4 |
So, what happens is each thread looks at the current value of accum and stores it to a thread-specific temporary variable. Each thread has its own memory, but they do all share the global variables.
Then thread 2 completes its calculation and updates temp2 and thread 1 updates temp1. So far everything is okay, but next thread 1 writes to accum and sets it to 1, and finally thread to writes to accum and makes it 4. The two values from the threads did not get added together, because thread 2 started before thread 1 finished.
So, we end up losing some of the values.
22.7. Locking#
We can instead change our square function. First we copy it
cp sq_sum_threaded.c sq_sum_locked.c
Then edit the copy
nano sq_sum_locked.c
so that the square function is like:
int accum = 0;
pthread_mutex_t accum_mutex = PTHREAD_MUTEX_INITIALIZER;
void* square(void* x) {
int xi = (int)x;
int temp = xi * xi;
pthread_mutex_lock(&accum_mutex);
accum += temp;
pthread_mutex_unlock(&accum_mutex);
return NULL; /* nothing to return, prevent warning */
}
then we build this:
gcc -pthread -Wall -g -o sqsuml sq_sum_locked.c -lm
sq_sum_locked.c:25:43: warning: cast to 'void *' from smaller integer type 'int'
[-Wint-to-void-pointer-cast]
pthread_create(&ths[i], NULL, square, (void*)(i + 1));
^
1 warning generated.
This version uses something from the pthread library, to create a lock.
Now when it executes each thread will do the calculation part on it’s own time, possibly simultaneously. Then the lock part means that they will each take turns to add their value to the global variable accum.
./sqsuml
accum = 2870
Now we all get the same result
for i in {1..1000}; do ./sqsuml; done | sort | uniq -c
1000 accum = 2870
and in our experiment, it comes out the same every time
cp sq_sum_threaded.c sq_sum.c
22.8. Review today’s class#
Review the notes.
Update your KWL chart.
Simulate a more computationally intensive program using the
sleepfunction in C and compare the time of a threaded vs single threaded (ie serial, no intentional threading) version of the program. Include your two programs and the bash script to show how you tested it with notes on the performance inthreaded.md(to better illustrate the impact of the threads)
22.9. Prepare for Next Class#
Create an issue called “Wrapping up” on your KWL repo. List what things you know you need to do to finish strong/get caught up, what you will do to figure out what you need, AND/OR what help you need.
Review your notes on IDE use
Preview the Stack Overflow Developer Survey Technology section for the languages.
22.10. More Practice#
Learn about the system libraries in two languages (one can be C or Python, one must be something else). Find the name(s) of the library or libraries. In
systeminteraction.mdsummarize what types of support are shared or different? What does that tell you about the language?(priority) Research examples of programs using multi-threading besides splitting up a single calculation for time reasons, include three examples in
whymultithread.md.